
Dégradation de la réponse du réseau neuronal lorsque le nombre de règles est surchargé
Principal » Postes sur le télégramme » Dégradation de la réponse du réseau neuronal lorsque le nombre de règles est surchargé

L'auteur du message n'est pas répertorié
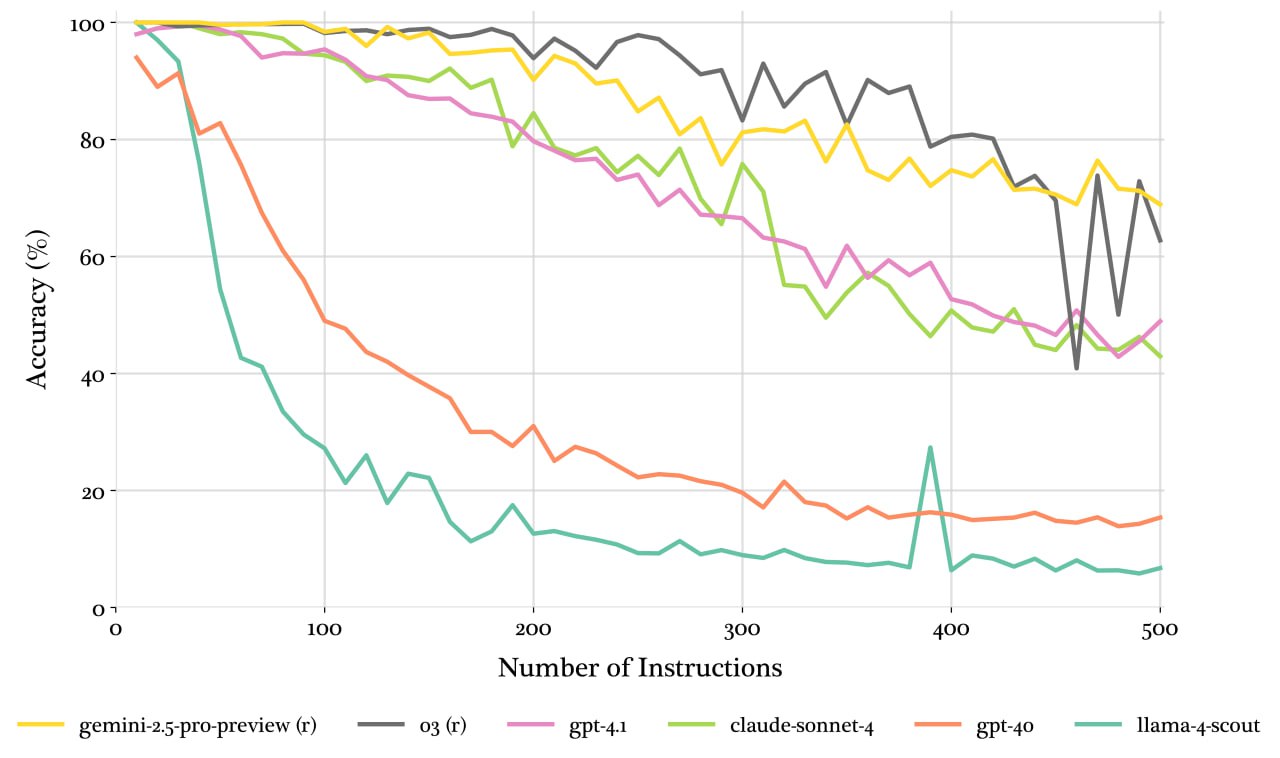
Dégradation de la réponse des réseaux neuronaux en cas de surcharge du nombre de règles à exécuter
Pour commencer, je vais brièvement analyser cette étude https://arxiv.org/html/2507.11538v1.
L'image montre comment les réseaux neuronaux se dégradent dans leur réponse à mesure que le nombre d'exigences dans le prompt augmente. Les exigences sont simples — rédiger un document professionnel et y insérer n mots spécifiques (tâche d'insertion de mots-clés). Verticalement — pourcentage de précision, horizontalement — nombre de règles.
L'étude est assez simple et semble plausible, mais ses conclusions dépendent des détails de la méthodologie.
Mais vous pouvez remarquer qu'il s'agit de vieux modèles. Et vous poser la question : « Et qu'est-ce qu'on en a à faire de vos vieilleries. Il y a déjà Gemini 3 : je vais y insérer 300 règles astucieuses — et je deviendrai un dresseur de LLM. »
Ne le prenez pas trop à cœur. Ce n'est pas à propos de vous. N'est-ce pas ? Oui..
Mais, malheureusement, ChatGPT-5.2 et Gemini 3 pro ne nous ont pas beaucoup rapprochés de l'AGI et donc ils ne respecteront pas non plus toutes les règles hétérogènes.
Exemple illustratif
J'avais la flemme de faire une expérience stricte, donc juste pour l'illustration et la confirmation de mes propos, j'ai effectué quelques tests pour moi-même et je vais montrer un exemple ici. D'autant plus que c'est assez prévisible : plus le prompt est complexe et plus il contient d'exigences, plus le respect des règles se dégrade rapidement.
L'essence du test : J'ai établi 77 règles banales pour la génération de texte, par exemple : écris toujours des paragraphes de 3 phrases ; utilise exactement 6 h2, 3 h3 sous chaque h2, et ainsi de suite.
Gemini doit créer le texte selon ces règles, et la vérification se fait via ChatGPT 5.2 Pro, pour mieux tout vérifier (moi-même, bien sûr, je n'ai pas envie de vérifier, donc nous prenons un modèle plus riche pour la vérification).
Deux exemples :
Et ainsi de suite. Plus on surcharge le LLM avec des règles et des tâches supplémentaires, moins elle les exécutera bien, car les ressources pour réfléchir et maintenir les exigences sont limitées. En même temps, l'augmentation des violations peut être liée non seulement aux « ressources », mais aussi aux conflits d'exigences et à la dilution des priorités.
À quoi mène l'incompréhension de cela
Cela conduit à des super-prompts, où un nombre infini de règles est inséré, qui sonnent de manière amusante et « technique », mais en fait, vous ne vérifiez souvent pas leur exécution, et une partie des règles, probablement, ne sera pas respectée.
Que faire
Segmenter les tâches et créer des prompts pour chaque segment et ne pas essayer de créer des prompts pour un niveau AGI. «Tu es un expert en SEO. Fais monter mon site dans le TOP, réalise un audit complet, collecte la sémantique, et en passant, fais aussi la promotion de ma fiche Yandex Business, et lorsque tu promouvras la fiche dans Yandex Business, sois un expert en SEO local, puis deviens un client qui évalue la fiche, si l'évaluation du travail ne dépasse pas le seuil de 4 sur 5, refais-le, et enfin active le mode agent, va sur le site du concurrent et laisse-y un mauvais avis».
Claude Code offre une nouvelle approche de l'automatisation des rapports SEO, permettant aux utilisateurs de créer des espaces de travail et de connecter des API pour simplifier les tâches de routine.
L'article traite du travail d'un agent non déterministe pour le référencement, de ses options de personnalisation et de ses différences par rapport aux générateurs de texte conventionnels. Les principales mesures et fonctionnalités sont décrites.
Ce document traite des systèmes d'IA non déterministes et de leurs avantages par rapport aux systèmes déterministes. Les possibilités de créer des flux uniques pour la génération de contenu sont examinées.
Cet article aborde l'idée d'une recherche approfondie pour la génération de textes par l'IA, y compris l'utilisation du système Deep Research de Google et de l'algorithme de recherche via Perplexity.
L'article décrit la création d'un mini-système de recherche pour démontrer le travail des algorithmes de recherche à l'aide de modèles d'IA modernes. Les possibilités et les perspectives de l'IA dans le développement de logiciels sont discutées.
Aucun article de l'auteur n'a été trouvé
AffGate.com est une plateforme d'analyse indépendante pour l'iGaming, le SEO et le marketing digital.
Nous collectons des données auprès de sources officielles, structurons l'information sur les marchés, les entreprises et les technologies, et rendons l'industrie plus transparente et compréhensible pour les professionnels.
AffGate.com n'est pas un casino en ligne et ne donne pas accès aux jeux d'argent. Toutes les informations sont disponibles à des fins éducatives et analytiques uniquement.
© 2024-2026 AffGate.com.




